
在通常的渲染流程中我们需要着色器,它一般输出的是RGBA值,而计算着色器则是比着色器更广泛的概念,我们可以自由配置GPU的核心,利用CPU的并行性来加速如大规模顶点计算等内容
unity版本:Unity6000.062f1
1、GPU
在了解计算着色器之前我们需要真正认识一下GPU,明明同样都是计算单元,为什么我们已经有CPU了还需要GPU呢。或许有人听说过CPU的优势在于计算速度,而GPU的优势则在于并行性。这很好的概括了两个处理器的特点。我们可以将CPU看作一个“好学生”,它的作业速度特别快可以快速处理非常复杂的难题,而GPU则相当于一整个学校数量的“普通学生”,他们虽然计算速度不快,但是如果有100份作业的话即使是好学生也需要写好久,而“普通学生”每人做一份,就可以用很快的速度做好这100份作业。所以我们可以这样粗略理解,GPU就是超级多运算速度较慢的CPU的集合。像渲染这种任务其实就像是这100份的作业大礼包,我们shader的着色任务就是将这100个像素的颜色计算出来,而GPU的每个核心(用NVIDIA的说法就是CUDA Core)同时计算这些像素的话,它当然就会比CPU一个一个计算要快很多很多。
2、计算着色器
普通的着色器(shader)是利用GPU的并行性来做渲染这种事情的,显而易见,GPU不止可以用来做这种事情,所以计算着色器(Compute Shader)出现了,它拥有比普通的着色器高的多的自由度,你甚至可以具体分配到底用几组核心来做哪些事情。例如我需要计算出大量粒子在空间中的位置,我需要生成某种特殊的图形,甚至是流体的模拟,光线追踪,我们都可以利用计算着色器来实现。
下面是Unity的默认计算着色器的代码:
#pragma kernel CSMain
RWTexture2D<float4> Result;
[numthreads(8,8,1)]
void CSMain (uint3 id : SV_DispatchThreadID)
{
Result[id.xy] = float4(id.x & id.y, (id.x & 15)/15.0, (id.y & 15)/15.0, 0.0);
}而下图则是这个代码生成的效果。

至于它所代表了什么,为什么会有这样的结果我们最后再说,现在只需要知道计算着色器可以做到这种事情就好。
2.1、kernel
我们看第一行:#pragma kernel CSMain
kernel 是内核的意思,而CSMain就是核函数,也就是最后要提交给GPU的指令,每个计算着色器至少要有一个核函数,可以有多个,会依次执行。
2.2、RWTexture2D
实际上就是申请个纹理,RW分别指读和写,意思是一个可读写的纹理。如果想要只读的话可以用Texture2D。
在通常的shader中,我们使用UV来读取纹理中的像素,而在计算着色器中,我们可以通过每个纹理中像素的下标来读取对应的值,如Result[uint2(0,0)]。此外我们也可以以同样的方式将其写入,写入的值当然就是float4,对应RGBA四个数值,例如我们可以利用这种方式制作程序化纹理,例如噪声等,以供正常shader的像素着色器使用。
而在计算着色器中除了RWTexture2D还有RWBuffer和RWStructuredBuffer等类型可以读写。后面也会依次介绍。
2.3、Numthreads
2.3.1、Thread
这是此文最重要的一点,正是它赋予了计算着色器的独特性。
首先我们要有个概念叫做线程(Thread),我们可以粗浅的理解为一个Thread就会执行一个任务,而在GPU中的一个个线程会被划分为多个线程组(Thread Group),一个Thread Group会在单个多留处理器(Stream Multiprocessor,简称SM)上被执行。例如我们的GPU有16个SM,就需要至少16个Thread Group来让GPU不“偷懒”,而为了避免某个SM已经做完某事而等待其他SM的情况,一般会给一个SM两个Thread Group让其可以在此时切换到下一个任务。
而
numthreads(tX, tY, tZ)指的就是一个Thread Group中Thread的数量,总量为tx * ty * tz个线程,例如numthreads(4, 4, 1) 和numthreads(16, 1, 1) 都指的是16个线程,一般我们会将它设置为64的整数倍个,这与NVIDIA和AMD的架构有关
NVIDIA会将一个线程组的线程分为一个个Warp,每个Warp中有32个线程,而Warp则通过SM来调度。所以对于NVIDIA的GPU来说,每次SM最少得调动一个Warp也就是32个线程,当我们将线程组中线程设置为10的时候,意味着其中有22个线程处于停工状态,以至于没法调动所有性能。
对AMD也是类似,它会将线程组中的线程分为一个个Wavefront,一个Wavefront中带有64个线程。
为了兼顾这两个显卡,一般我们倾向于将线程组中的线程数设置为64的整数倍个。
此外,线程组中的线程是有限制的,一般最多只有1024个
2.3.2、Thread的ID
又回到numthreads(tX, tY, tZ)上面,我们可以看到一个线程是由三维的关系来表示的,我们还可以用之前学生的例子,我们想要找到某个学生(线程)的话,就需要知道这个学生在那排那列(X,Y),可是我们不止有一个班级,一层楼里可能有多个班级,所以我们需要定位那班(Z)
虽然这样能表示的线程很多,足足有1024个,但其实远远不够我们的需求,例如我们用Computer Shader来处理一张贴图,一个线程处理一个像素的话,那我们也就只能同时处理1024个像素,而我们需要处理的像素或许有1920*1080之多。
这就需要多个线程组,与线程相对的,线程组也有好多好多个,用类似 computeShader.Dispatch(kernel, 60, 34, 1);的方式表示,它同样也是三维结构。那我们可以这样想象,一个学校有多栋楼,一个线程组就是某个楼的某一层,那么,我们想要某个层的话,就需要知道它到底在哪个楼的哪一层(X,Y),而这个市有多个学校,那么我还需要知道具体是哪个学校(Z)。想要精确的找到某个同学,我们就需要找到学校、大楼、楼层、班级、横列、纵列。
下图来自于微软关于HLSL的介绍,表示了线程组和线程之间的关系。
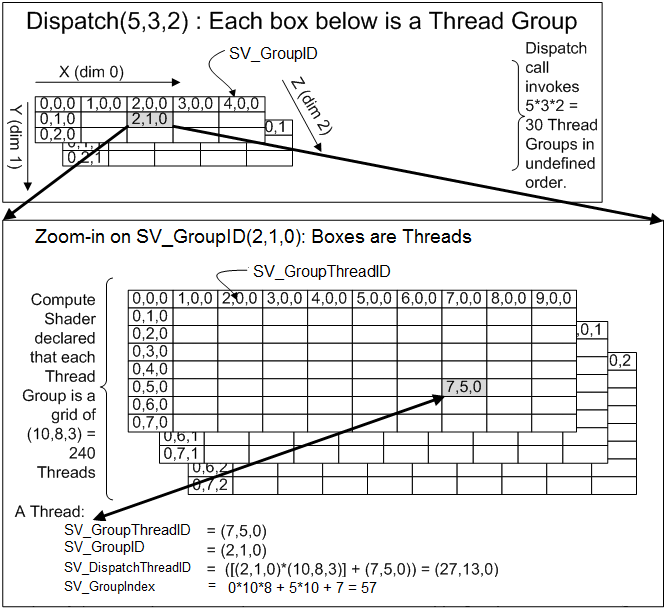
上面提到了4种ID,分别是SV_GroupID、SV_GroupThreadID、SV_DispatchThreadID、SV_GroupIndex。他们所代表的含义如下表:
| 参数 | 值类型 | 含义 | 计算公式 |
|---|---|---|---|
| SV_GroupID | int3 | 当前线程所在的线程组的ID,取值范围为(0,0,0)到(gX-1,gY-1,gZ-1)。 | 无 |
| SV_GroupThreadID | int3 | 当前线程在所在线程组内的ID,取值范围为(0,0,0)到(tX-1,tY-1,tZ-1)。 | 无 |
| SV_DispatchThreadID | int3 | 当前线程在所有线程组中的所有线程里的ID,取值范围为(0,0,0)到(gX * tX-1, gY * tY-1, gZ * tZ-1)。 | 假设该线程的SV_GroupID=(a, b, c),SV_GroupThreadID=(i, j, k) 那么SV_DispatchThreadID=(a * tX+i, b * tY+j, c * tZ+k) |
| SV_GroupIndex | int | 当前线程在所在线程组内的下标,取值范围为0到tX * tY * tZ-1。 | 假设该线程的SV_GroupThreadID=(i, j, k) 那么SV_GroupIndex=k * tX * tY+j * tX+i |
让我再拿刚才的比喻说明下各个ID的含义(要牢记计算机的世界中数字是从0开始的)。
SV_GroupID
指的就是现在这个学生的楼层编号。
例如:
SV_GroupID = (2,1,0)指的是这个学生在这个市的第1所学校上学,在这个学校的第3栋楼的第2层
SV_GroupThreadID
指的是这个学生的座位在哪
例如:
SV_GroupThreadID = (7,5,0)指的就是这个学生在当前所在这个楼层的第1个教室、第8列,第6行
SV_GroupIndex
我们现在假设一个楼层是一整个年级,我们对整个年级的所有学生进行一个排号,SV_GroupIndex指的是这个学生在这个年级的号是多少。
还是这个学生:
SV_GroupThreadID = (7,5,0)而整个楼层(年级)所能容纳的学生是
numthreads(10, 8, 3)一共240人
我们前面有0个班级,一共0x10*8=0个人,在我们前面有5排,一排10个人一共5x10=50人,而我们在第六排的第8名
所以我们是第0x10*8+5x10+8=58号,而在计算机的世界中编号是从0开始。所以实际上是第57号。
SV_DispatchThreadID
这次我想要知道这个学生在整个市的排名(SV_DispatchThreadID),不过我们使用的形式并不是某个数字,而是以矩阵的形式。
我们假设这个市里有2个学校,每个学校有三个教学楼,每个教学楼有五层
Dispatch(5,3,2)然后每层有3个教室,10列,8行
numthreads(10, 8, 3)还是这个同学:第一个学校,第三个教学楼,二层
第一个教室,第七列,第五排
SV_GroupID = (2,1,0)
SV_GroupThreadI = (7,5,0)那么就是
(2,1,0)* (10,8,3) = (20,8,0)
(20,8,0) + (7,5,0) = (27 , 13 , 0)
(27 , 13 , 0) = 27 * 13 = 3512.3.3、Thread的ID的使用
讲了这么多关于ID的内容,肯定是他实际上是有用的,我们可以在写核函数的时候引入这些ID
如
void CSMain (uint3 id : SV_DispatchThreadID)
{
Result[id.xy] = float4(id.x & id.y, (id.x & 15)/15.0, (id.y & 15)/15.0, 0.0);
}我们当然也可以拿到所有自己想要的ID
void KernelFunction(uint3 groupId : SV_GroupID,
uint3 groupThreadId : SV_GroupThreadID,
uint3 dispatchThreadId : SV_DispatchThreadID,
uint groupIndex : SV_GroupIndex)
{
}当我们想要给纹理的像素赋值的时候,如果是以前的CPU中我们就需要一个一个赋予:
for (int i = 0; i < x; i++)
for (int j = 0; j < y; j++)
Result[uint2(x, y)] = float4(a, b, c, d);而现在我们有了一大堆线程,我们可以同时让每个线程给一个像素赋值,这时候这些ID就起作用了,还记得untiy的示例代码吗:[numthreads(8,8,1)]。
其中每个线程组中有64个线程,当我们使用SV_DispatchThreadID的时候,第一个线程组(0,0,0)的ID就是(0,0)~(7,7) ,第二个线程组(1,0,0)则是(8,0)~(7,15)对于第(a,b,0)个线程组,他的取值范围就是(ax8, bx8, 0)到(ax8+7, bx8+7, 0)。那么如果我们想要处理分辨率为1024*1024 的图,我们只需要dispatch(1024/8, 1024/8, 1)个线程组。
从前需要一个一个赋值的图像,我们只需要
Result[uint2(SV_DispatchThreadID.x,SV_DispatchThreadID.y)] = float4(a, b, c, d);就可以全部赋值。
至于其他ID则可以类似这样自由灵活的使用,这里就不举例了。